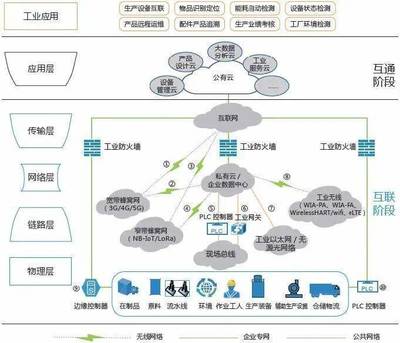
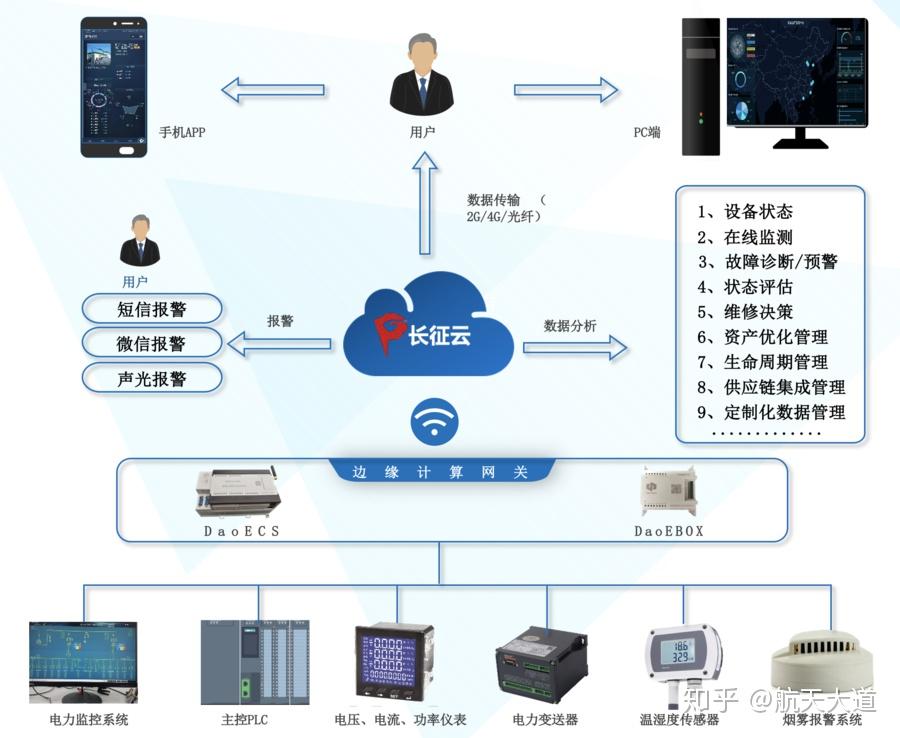
企業會員分層數據分析的抽樣修正方法 工業互聯網數據服務視角

在工業互聯網數據服務中,企業會員分層數據分析是優化用戶運營、提升服務效率的關鍵環節。當樣本量大于100時,抽樣誤差雖然相對減小,但仍需采用適當的修正方法以確保數據代表性和分析準確性。以下是幾種適用于工業互聯網場景的抽樣修正方法:
一、分層抽樣修正法
在工業互聯網數據服務中,企業會員通常根據行業、規模、使用頻率等維度分層。當樣本量超過100時,可采用分層比例調整法:先計算各層在實際總體中的比例,再根據樣本中各層的分布情況進行加權修正。例如,若某行業企業占比為30%,但樣本中僅占20%,則需對該層數據賦予更高權重,以還原總體特征。
二、回歸修正法
利用工業互聯網平臺積累的歷史數據,建立會員行為預測模型。通過回歸分析,識別樣本與總體之間的系統性偏差,并對抽樣結果進行校正。例如,針對會員活躍度數據,可用平臺整體活躍趨勢作為自變量,修正抽樣樣本的偏差值。
三、Bootstrap重抽樣技術
對于大于100的樣本,可采用Bootstrap方法進行多次重抽樣,生成大量模擬樣本,進而計算統計量的分布區間。這種方法特別適用于工業互聯網場景中數據分布不確定的情況,能有效降低抽樣隨機性帶來的誤差。
四、事后分層修正
在數據收集完成后,根據工業互聯網平臺掌握的企業會員總體特征(如地域分布、行業分類等),對樣本進行事后分層處理。通過計算各層的調整因子,對原始抽樣數據進行校準,使其更貼近總體分布。
五、貝葉斯修正方法
結合先驗知識(如行業專家經驗、歷史數據分析結果)和抽樣數據,采用貝葉斯方法進行參數估計。這種方法在工業互聯網數據服務中尤為實用,能夠將領域知識與實際抽樣數據有機融合。
實施建議:
在工業互聯網數據服務實踐中,建議組合使用多種修正方法,并進行敏感性分析。同時,應建立持續監測機制,定期評估抽樣策略的有效性,及時調整修正參數。考慮到工業互聯網數據的動態特性,修正方法應具備一定的適應性,能夠隨著企業會員結構和行為模式的變化而調整。
通過科學合理的抽樣修正方法,工業互聯網數據服務商能夠從有限樣本中獲取更準確的企業會員洞察,為產品優化、精準營銷和戰略決策提供可靠的數據支撐。
如若轉載,請注明出處:http://m.epmm.com.cn/product/29.html
更新時間:2026-01-06 22:49:12